自动答题软件原理(自动答题软件原理图)

文章摘要
自动答题软件作为一种基于人工智能技术的应用,其核心原理涉及多学科交叉融合。本文将从技术架构、数据采集与处理、自然语言理解、知识库构建、算法模型以及应用场景六个维度,系统解析自动答题软件的工作原理。软件通过光学字符识别(OCR)和网络爬虫实现题目采集,借助自然语言处理(NLP)技术解析语义,依托知识图谱和机器学习构建动态知识库,最终通过深度学习模型生成答案。整个过程体现了数据驱动的智能化特征,但也面临与技术边界的争议。下文将逐一展开论述,揭示其技术本质与应用价值。
一、技术架构与模块设计
自动答题软件的系统架构通常采用分层设计模式。基础层包含硬件支持与数据接口,负责物理设备交互和原始数据输入;中间层由算法引擎和知识管理模块构成,完成核心计算任务;应用层则实现用户界面与结果输出。各模块通过API接口实现松耦合连接,保证系统可扩展性。
在具体实现中,流程控制模块负责协调OCR识别、语义分析、答案检索等子系统的协同工作。异常处理机制通过实时监控各环节运行状态,确保错误数据能触发重试或人工干预。分布式计算框架的引入,使得大规模并发请求处理成为可能。
模块间的数据流转遵循严格协议,原始题目经预处理后转化为结构化数据,再进入分析管道。这种设计既保证处理效率,又便于后期功能迭代。当前主流系统普遍采用微服务架构,单个模块故障不会导致整体瘫痪。
二、数据采集与预处理技术
数据输入端采用多模态采集策略。OCR技术可解析图片/手写体题目,准确率已达98%以上;网络爬虫实时抓取教育平台题库,配合反爬机制实现可持续数据更新;语音识别模块则将音频题目转为文本。采集过程中需处理噪声数据过滤、格式标准化等问题。
预处理环节包含关键数据清洗步骤。通过正则表达式匹配去除乱码字符,利用文本纠错算法修正拼写错误,采用词干提取技术统一不同词形。对于数学公式等特殊内容,LaTeX解析器确保符号系统的准确转换。
数据标注体系直接影响后续分析质量。系统自动标注题目类型(选择题/简答题)、学科分类、难度系数等元数据,同时建立错题反馈机制。用户纠错数据经审核后反哺标注系统,形成动态优化闭环。
三、自然语言理解与语义分析
语义解析采用分层处理模式。词法分析首先完成分词与词性标注,句法分析构建依存关系树,语义角色标注识别题目中的核心要素。对于多义词消歧,系统结合上下文语境与学科知识库进行概率推断。
深度语义理解依赖预训练语言模型。基于Transformer架构的BERT变体在捕捉长距离语义关联方面表现突出,能有效识别题目中的隐含条件。注意力机制帮助模型聚焦关键信息点,如数学题中的变量关系或历史题的时间线索。
如果认准备考,可联系网站客服获取针对性考试资料!
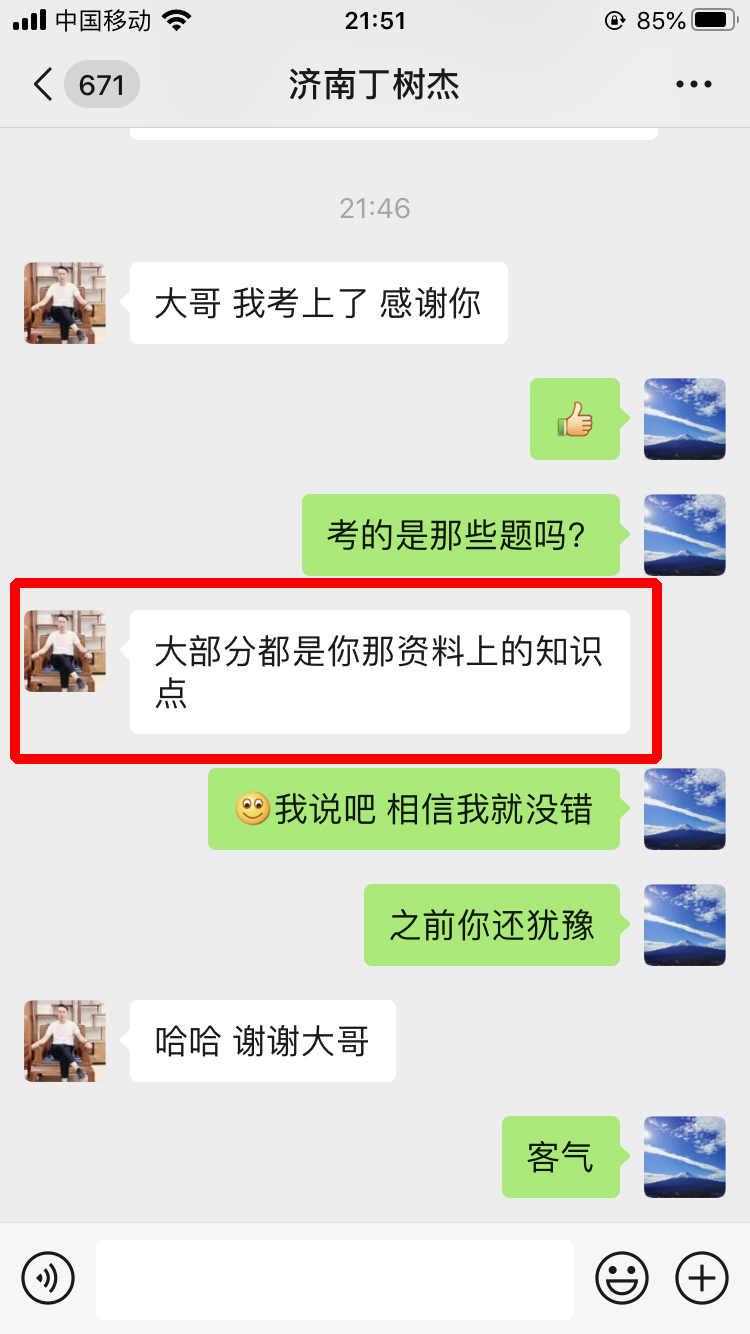
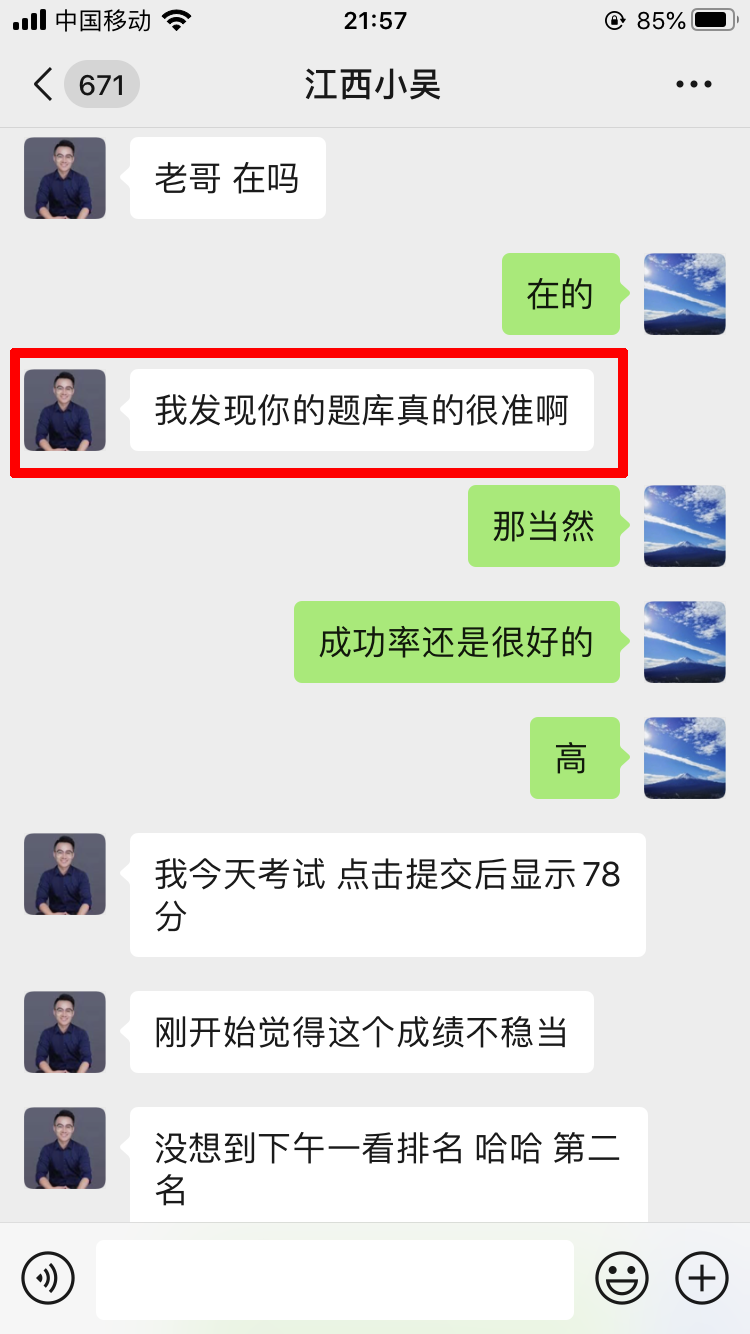
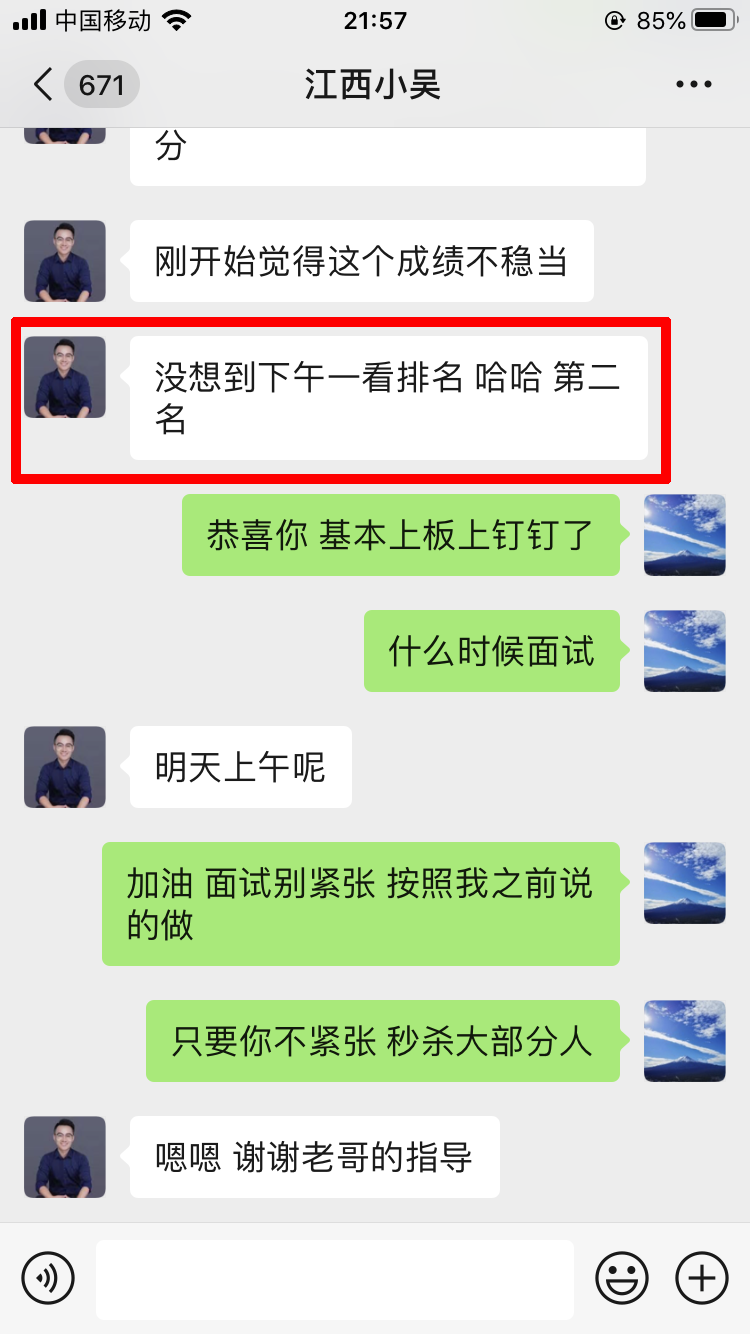
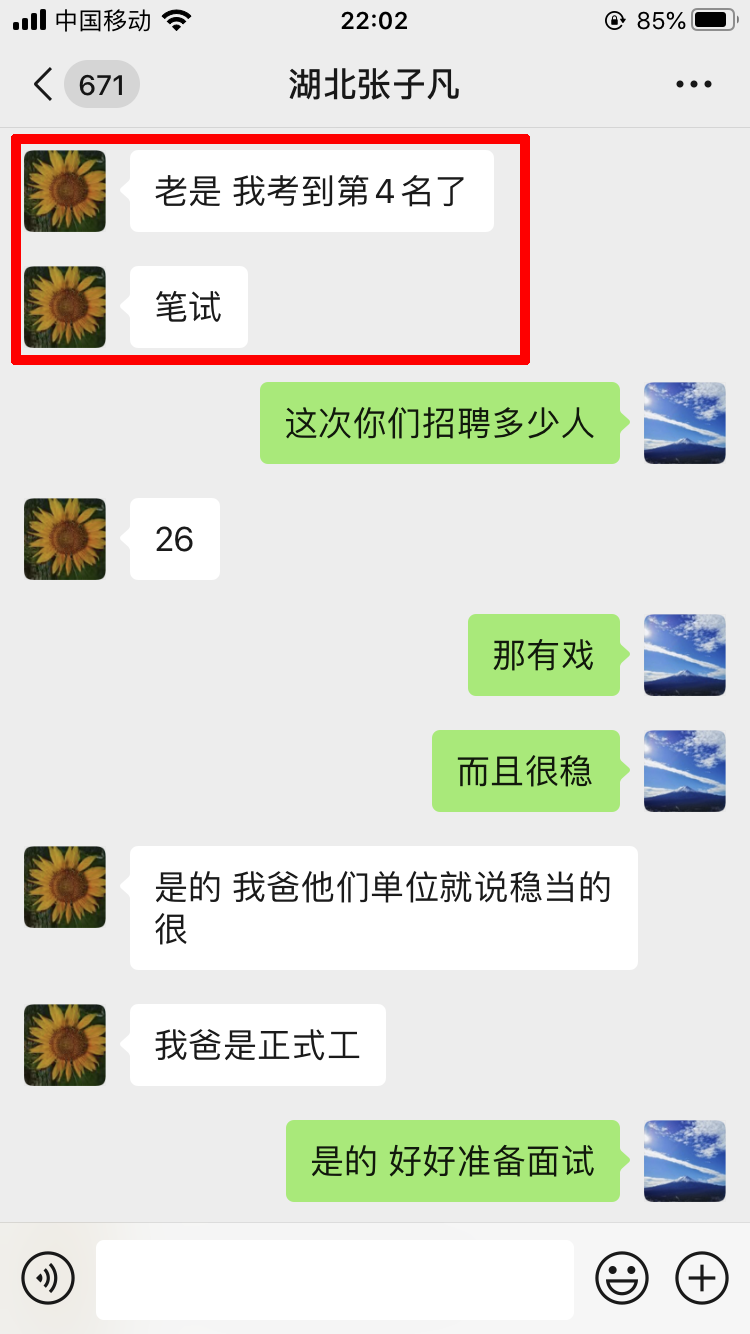
学员评价
推荐阅读:
- 上一篇:答题神器电脑版免费版(答题神器网页版)
- 下一篇:没有了
