题库自动答题脚本怎么写好 题库自动答题脚本怎么写好一点

文章摘要
题库自动答题脚本的开发需要兼顾效率、准确性和安全性。本文将从六个关键方面详细探讨如何优化脚本设计:首先明确题库来源与数据结构,其次选择合适的技术栈,接着优化匹配算法,然后处理反作弊机制,再完善错误处理与日志记录,最后强调代码可维护性。通过系统化的方法,开发者可以打造出高效、稳定且适应性强的自动答题工具,同时规避法律与风险。
---
1. 题库来源与数据结构设计
题库的质量直接影响脚本的准确性。优先选择权威、更新频繁的题库,如教育机构公开资源或专业平台API。避免使用来路不明的数据,以免引发版权问题或答案错误。
数据结构设计需高效支持查询。推荐使用键值对数据库(如Redis)存储题目-答案映射,或通过哈希表实现快速匹配。对于复杂题型(如多选题),需设计嵌套结构以保存关联关系。
定期更新题库是长期稳定的关键。可编写爬虫脚本定时同步最新题目,或设置用户反馈通道修正错误答案,形成动态维护机制。
2. 技术栈选择与性能优化
根据场景选择编程语言。Python适合快速开发且库丰富(如Requests、BeautifulSoup),但性能要求高时可考虑Go或Rust。浏览器自动化工具(如Selenium或Puppeteer)适用于网页端答题。
减少不必要的网络请求。本地缓存高频题目,或预加载题库到内存中,避免每次查询都访问数据库。多线程技术可提升批量答题效率,但需注意线程安全。
性能监控不可或缺。通过工具(如cProfile)分析脚本耗时,优化瓶颈代码。例如,正则表达式匹配可能比字符串遍历更快,但需测试实际效果。
3. 智能匹配算法的实现
基础关键词匹配可能误判。结合TF-IDF或余弦相似度计算题目文本相似性,提高模糊匹配准确率。对选择题,可提取选项特征(如长度、数字占比)辅助判断。
处理题目变体时需灵活应对。例如,同一问题可能以不同句式提问,可通过自然语言处理(NLP)技术归一化文本,或建立同义词库扩展匹配范围。
引入机器学习模型(如BERT)处理复杂语义匹配,但需权衡训练成本与收益。小规模场景下,规则引擎可能是更实用的选择。
4. 反作弊机制的规避策略
模拟人类操作降低检测风险。随机化答题间隔时间,添加鼠标移动轨迹模拟,避免固定模式触发风控。动态更换User-Agent和IP地址进一步隐藏自动化特征。
分析目标平台的反作弊逻辑。例如,某些系统会检测剪贴板使用或快速焦点切换。通过逆向工程或社区经验,针对性绕过限制。
法律与边界需严守。仅将脚本用于合法自测或授权场景,避免破坏公平性。开源代码时移除敏感逻辑,防止滥用。
如果认准备考,可联系网站客服获取针对性考试资料!
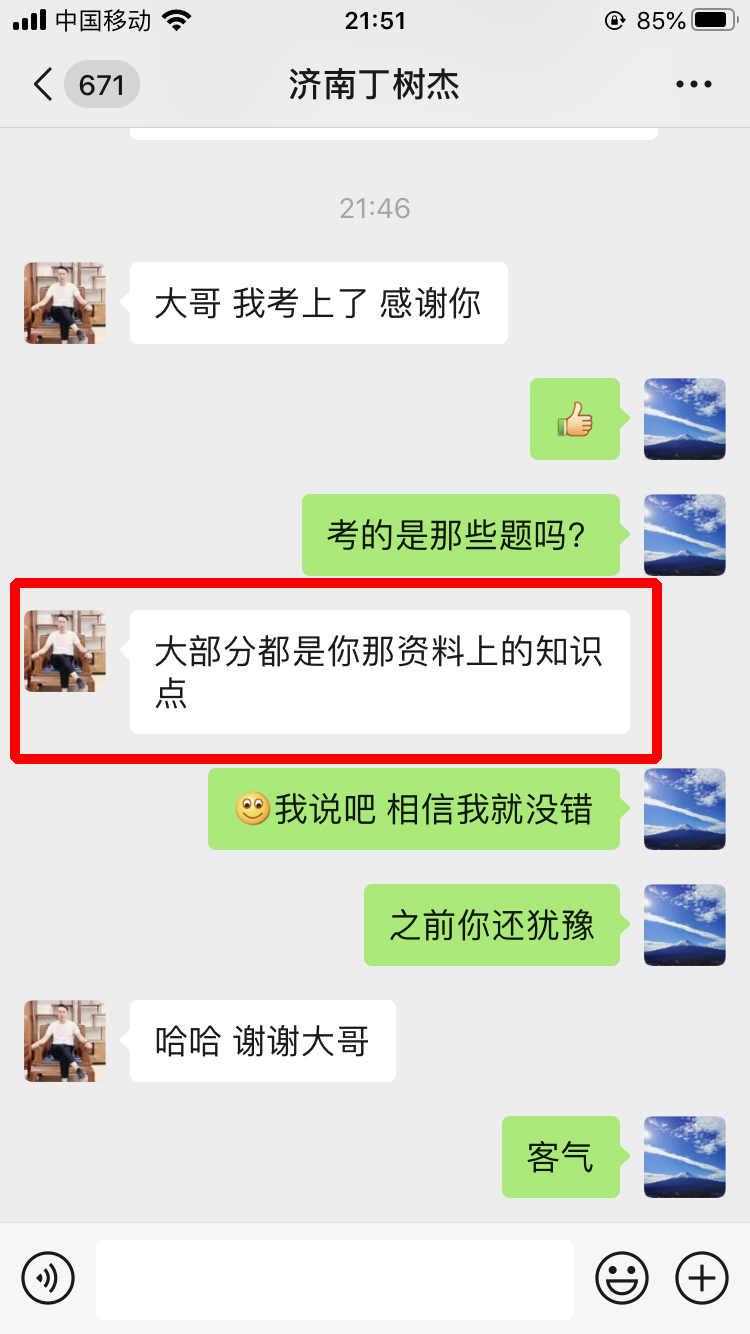
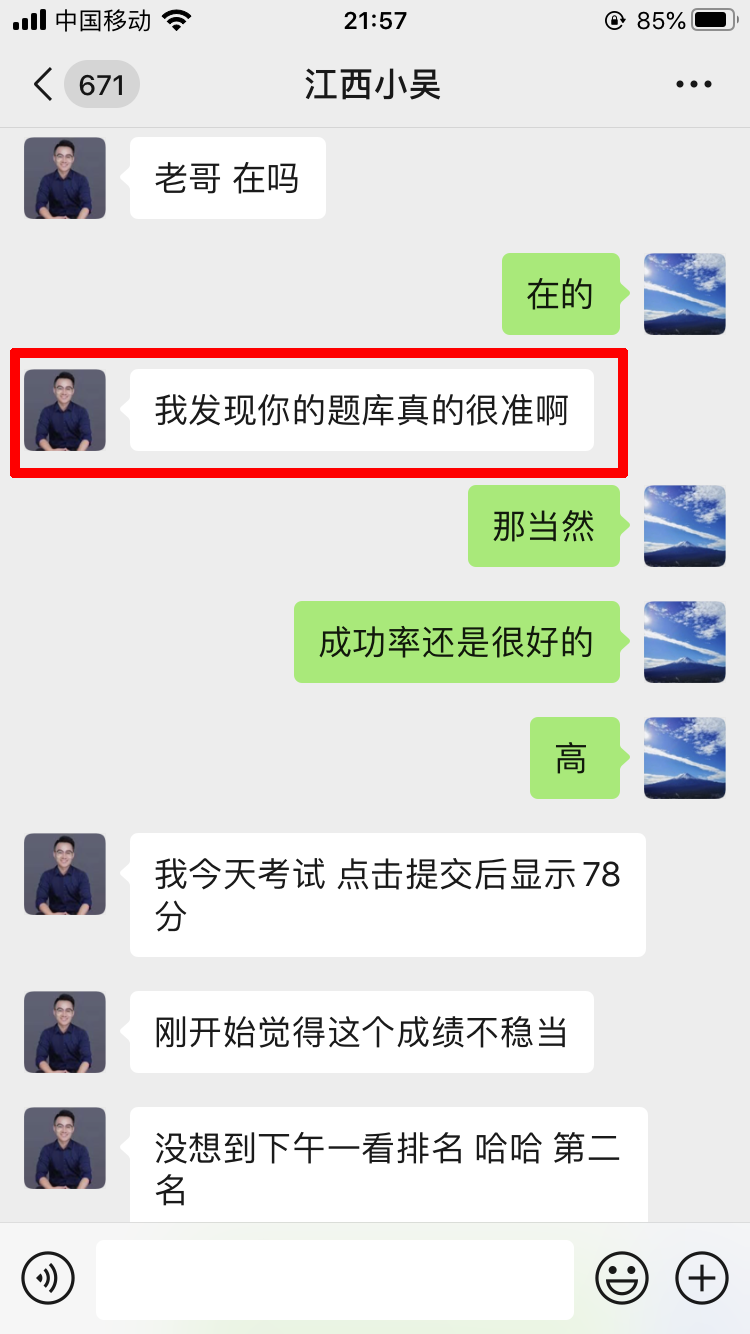
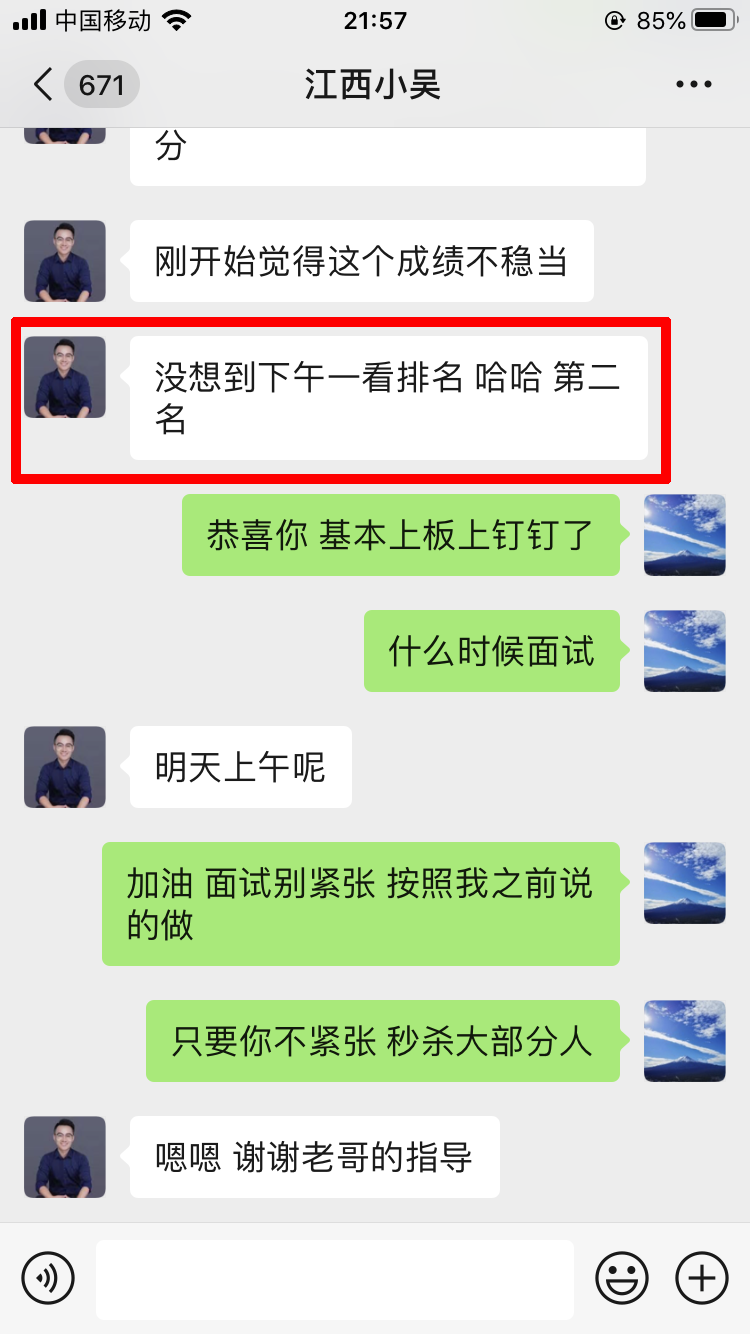
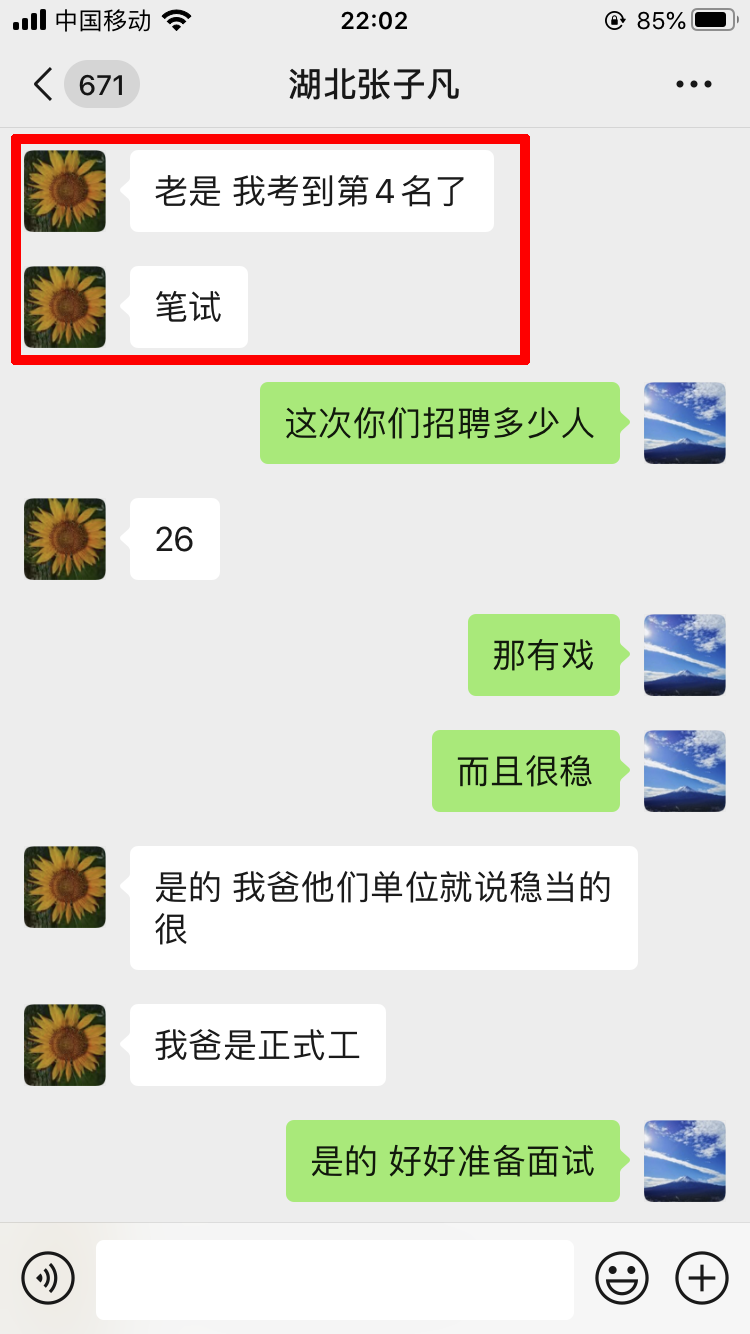
学员评价
推荐阅读:
- 上一篇:魔域智力竞赛答题库及答案 魔域智力竞赛答题库及答案大全
- 下一篇:没有了
