自动搜题的脚本 自动搜题的脚本怎么写

文章摘要
本文详细探讨了如何编写自动搜题的脚本,旨在为开发者提供全面的指导。文章从六个方面展开:需求分析、技术选型、数据抓取、题目解析、结果匹配和脚本优化。每个方面都通过多个自然段深入阐述,帮助读者理解编写自动搜题脚本的关键步骤和技术细节。通过本文,读者将掌握从需求分析到脚本优化的完整流程,能够独立开发高效的自动搜题工具。
正文
1. 需求分析
在编写自动搜题的脚本之前,首先需要进行详细的需求分析。这一步骤至关重要,因为它决定了脚本的功能和性能。需求分析的第一步是明确脚本的使用场景。例如,脚本是为学生提供作业帮助,还是为教师批改试卷?不同的使用场景决定了脚本需要处理的问题类型和复杂度。
需求分析还包括确定脚本的输入和输出。输入通常是一道题目,而输出则是题目的答案或相关解析。在这一过程中,需要考虑题目的格式,如选择题、填空题或简答题,以及题目可能包含的图片、公式等复杂元素。
需求分析还需要考虑脚本的性能要求。例如,脚本是否需要在短时间内处理大量题目?是否需要支持多语言或多种题型?这些问题的答案将直接影响后续的技术选型和开发策略。
2. 技术选型
技术选型是编写自动搜题脚本的核心环节之一。需要选择合适的编程语言。Python 是一个广泛使用的选择,因为它有丰富的库和强大的社区支持。JavaScript 和 Java 也是不错的选择,具体取决于开发者的熟悉程度和项目需求。
需要选择合适的数据抓取工具。常用的工具包括 BeautifulSoup 和 Scrapy,它们可以帮助从网页中提取题目和答案。对于需要处理动态内容的网站,可能还需要使用 Selenium 或 Puppeteer 等工具。
技术选型还包括选择合适的题目解析和匹配算法。例如,自然语言处理(NLP)技术可以用于解析题目文本,而机器学习算法可以用于提高题目匹配的准确性。
3. 数据抓取
数据抓取是自动搜题脚本的关键步骤之一。需要确定抓取的目标网站。这些网站通常是教育平台、题库或论坛,其中包含大量的题目和答案。在抓取之前,需要了解目标网站的结构,包括网页的URL格式、题目的存放位置以及答案的显示方式。
需要编写抓取脚本。抓取脚本通常包括以下几个步骤:发送HTTP请求、解析网页内容、提取题目和答案,并将数据存储到本地或数据库中。在这一过程中,需要注意遵守目标网站的 robots.txt 文件和使用条款,避免非法抓取。
数据抓取还需要考虑反爬虫机制。许多网站会使用验证码、IP封禁等手段防止数据被抓取。为了应对这些机制,可能需要使用代理IP、设置请求头或使用验证码识别工具。
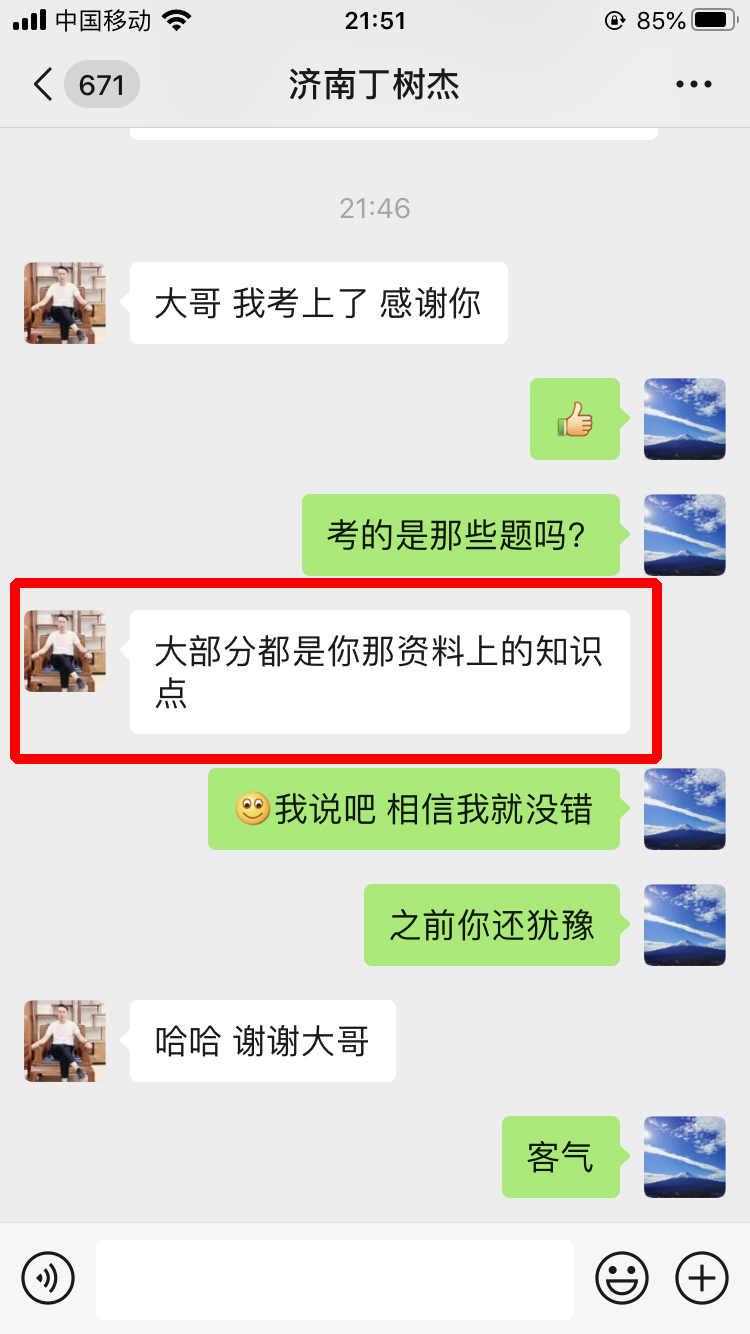
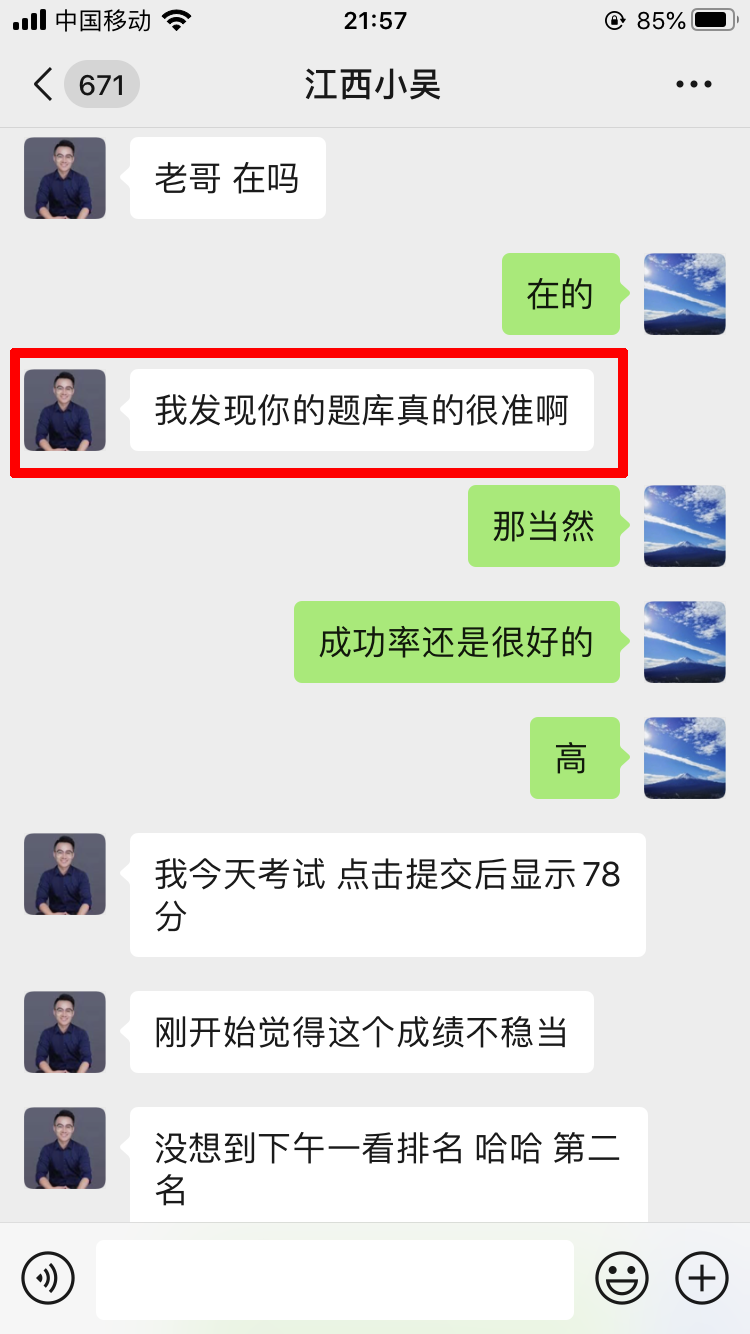
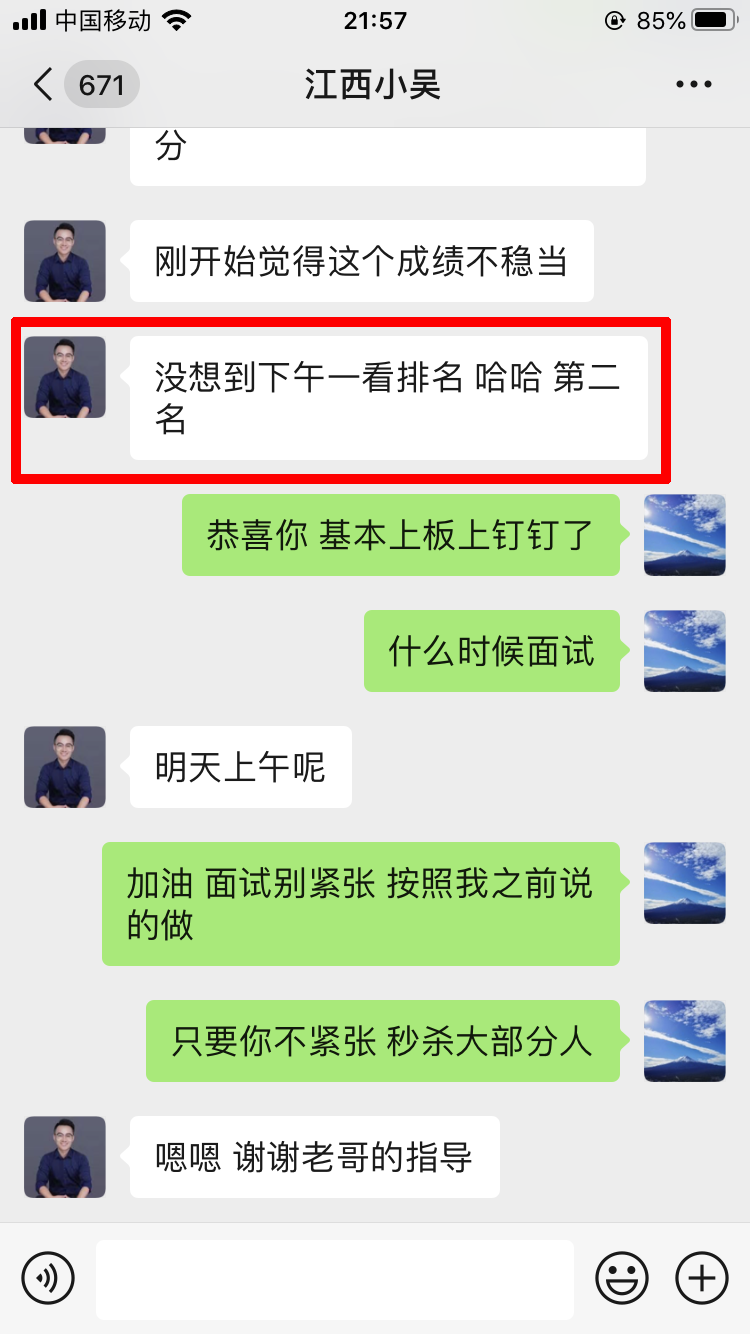
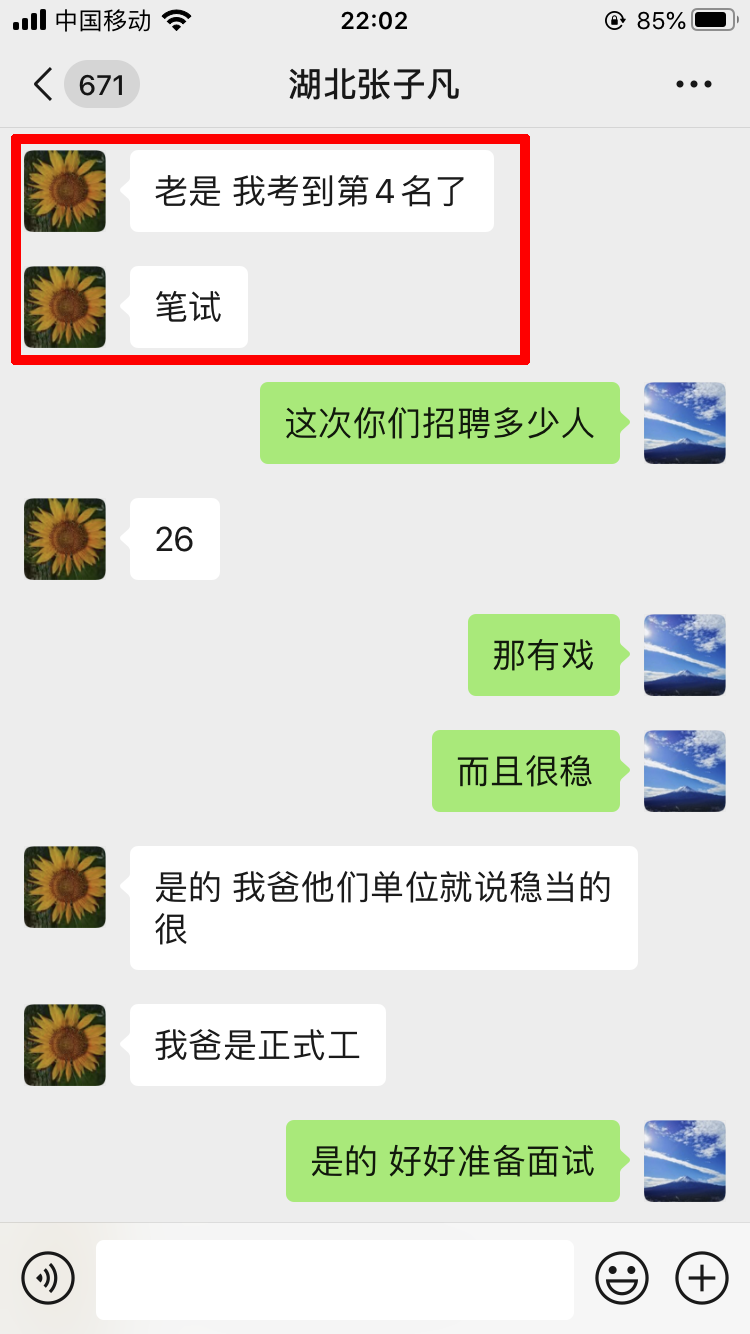
学员评价
推荐阅读:
- 上一篇:苹果手机自带搜题 苹果手机自带搜题功能
- 下一篇:没有了