2025年自动搜题的脚本怎么做出来的呢(自动搜题的脚本怎么做出来的呢图片)

自动搜题的脚本怎么做出来的呢?
在当今信息爆炸的时代,学生和教育工作者面临着大量的学习资料和题目,手动搜题不仅费时费力,还容易错过一些关键信息。为了提高效率,自动搜题的脚本应运而生。本文将详细介绍如何制作一个自动搜题的脚本,并通过图片展示其工作原理。
1. 脚本开发基础
编程语言选择
选择合适的编程语言是开发自动搜题脚本的第一步。Python因其简洁易用和丰富的库支持,成为首选。Python的`requests`库可以用于发送HTTP请求,`BeautifulSoup`库则用于解析网页内容。
环境搭建
在开始编写脚本之前,需要搭建一个合适的开发环境。安装Python解释器,并配置好相关的库。推荐使用Anaconda或PyCharm等集成开发环境,以便更好地管理项目和调试代码。
基础知识储备
开发者需要具备一定的编程基础,特别是对Python的基本语法和数据结构有所了解。了解HTML和CSS的基本知识也有助于理解网页结构和内容提取。
2. 网页抓取技术
HTTP请求发送
自动搜题脚本的核心是网页抓取。使用`requests`库发送HTTP请求,获取目标网页的HTML内容。通过设置请求头,模拟浏览器行为,避免被网站的反爬机制拦截。
网页内容解析
获取到网页内容后,需要对其进行解析,提取出题目和答案。`BeautifulSoup`库提供了强大的HTML解析功能,可以方便地定位和提取所需信息。
数据存储
解析后的数据需要进行存储,以便后续使用。可以使用SQLite或MongoDB等数据库,也可以将数据保存为CSV或JSON格式。选择合适的存储方式,取决于数据的规模和使用场景。
3. 题目识别与提取
题目类型判断
不同类型的题目有不同的特征,如选择题、填空题、简答题等。脚本需要能够识别题目的类型,并根据类型进行相应的处理。可以通过正则表达式或机器学习模型来实现题目类型判断。
题目内容提取
提取题目内容是自动搜题脚本的关键步骤。通过分析HTML结构,定位题目所在的标签,并提取出题目的文本内容。可以使用XPath或CSS选择器来精确定位题目元素。
答案提取与匹配
在提取题目内容的还需要提取出对应的答案。答案通常位于题目的下方或相关链接中。脚本需要能够识别答案的标识符,并将其与题目进行匹配。
4. 图片处理与识别
图片获取与下载
有些题目或答案以图片形式存在,脚本需要能够识别并下载这些图片。使用`requests`库发送图片请求,并将其保存到本地。
图片内容识别
下载的图片需要进行内容识别,提取出其中的文字信息。可以使用OCR(光学字符识别)技术,如Tesseract,将图片中的文字转换为可编辑的文本。
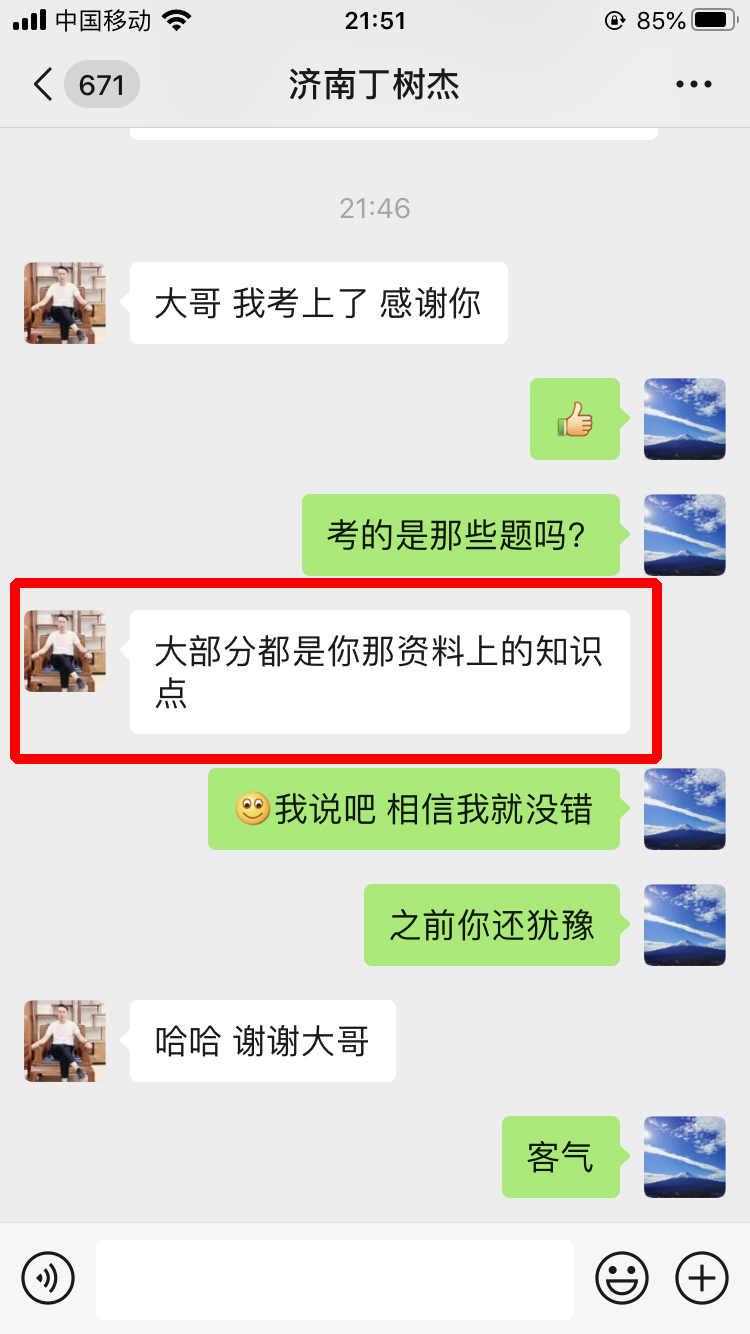
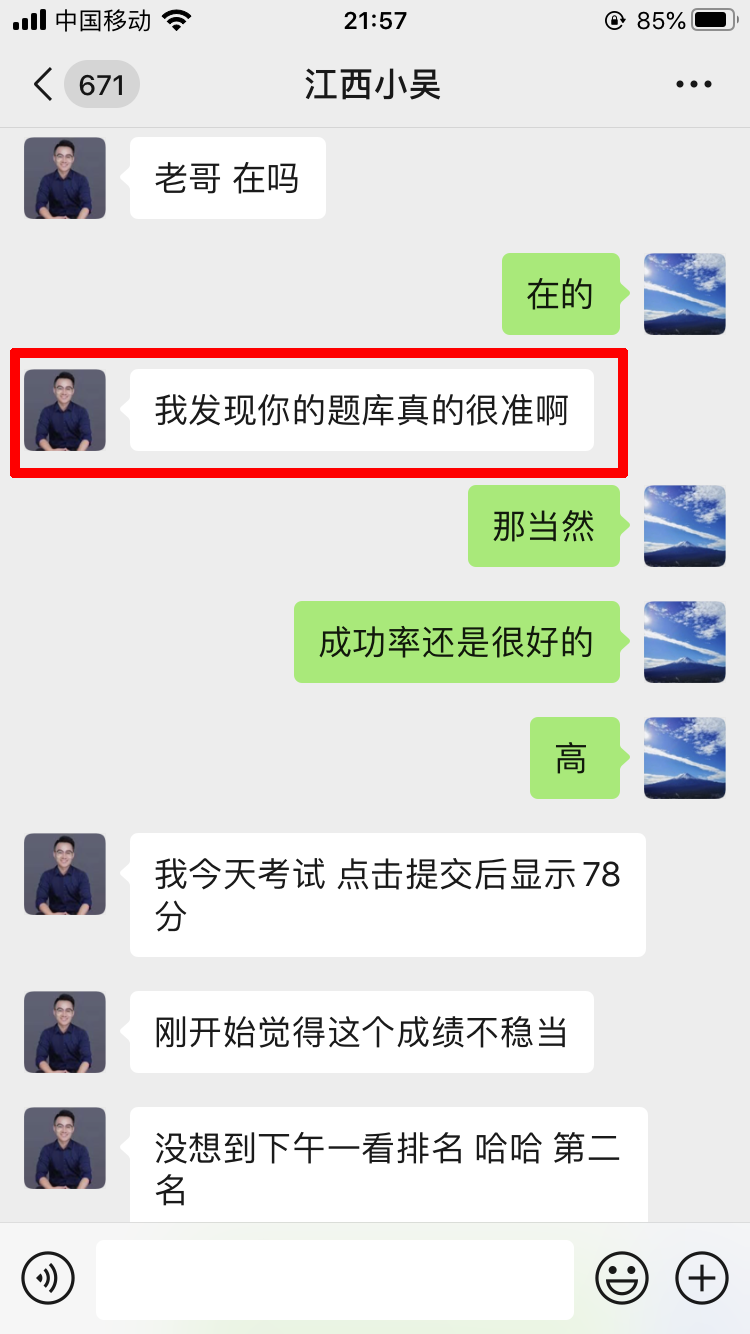
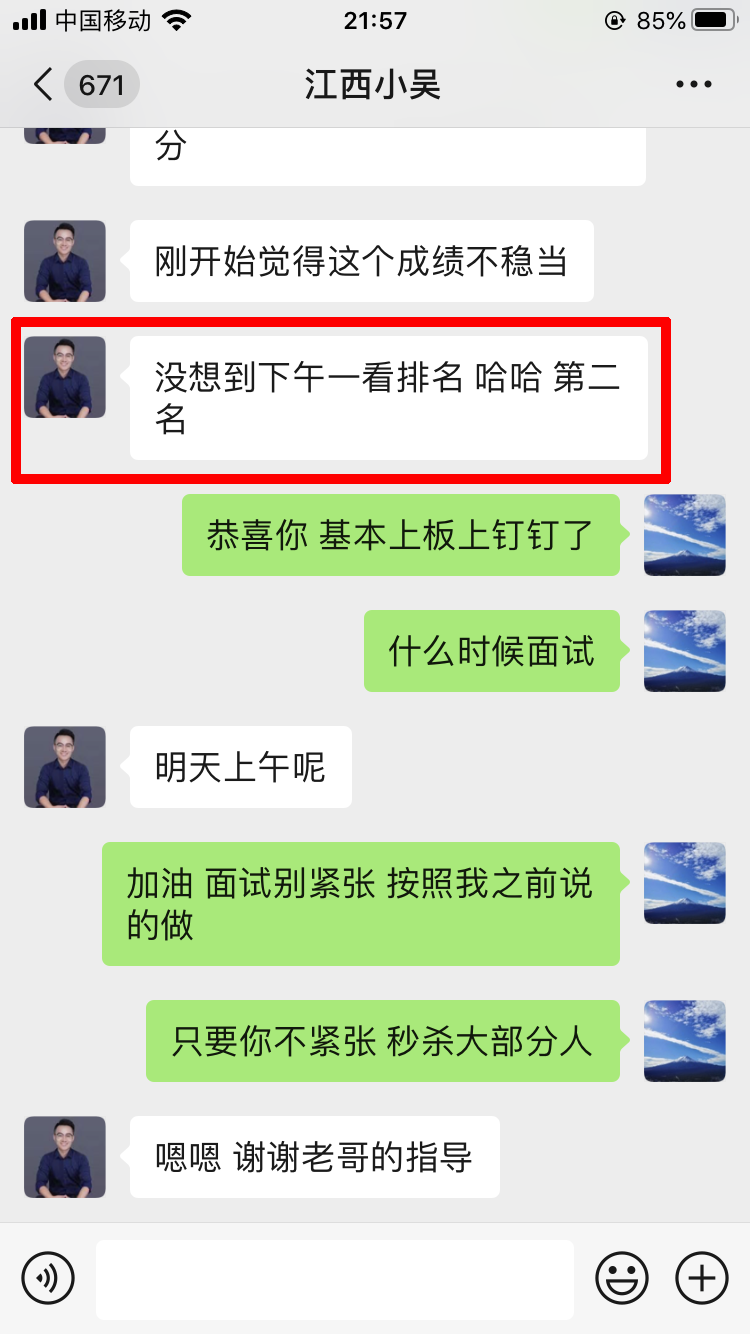
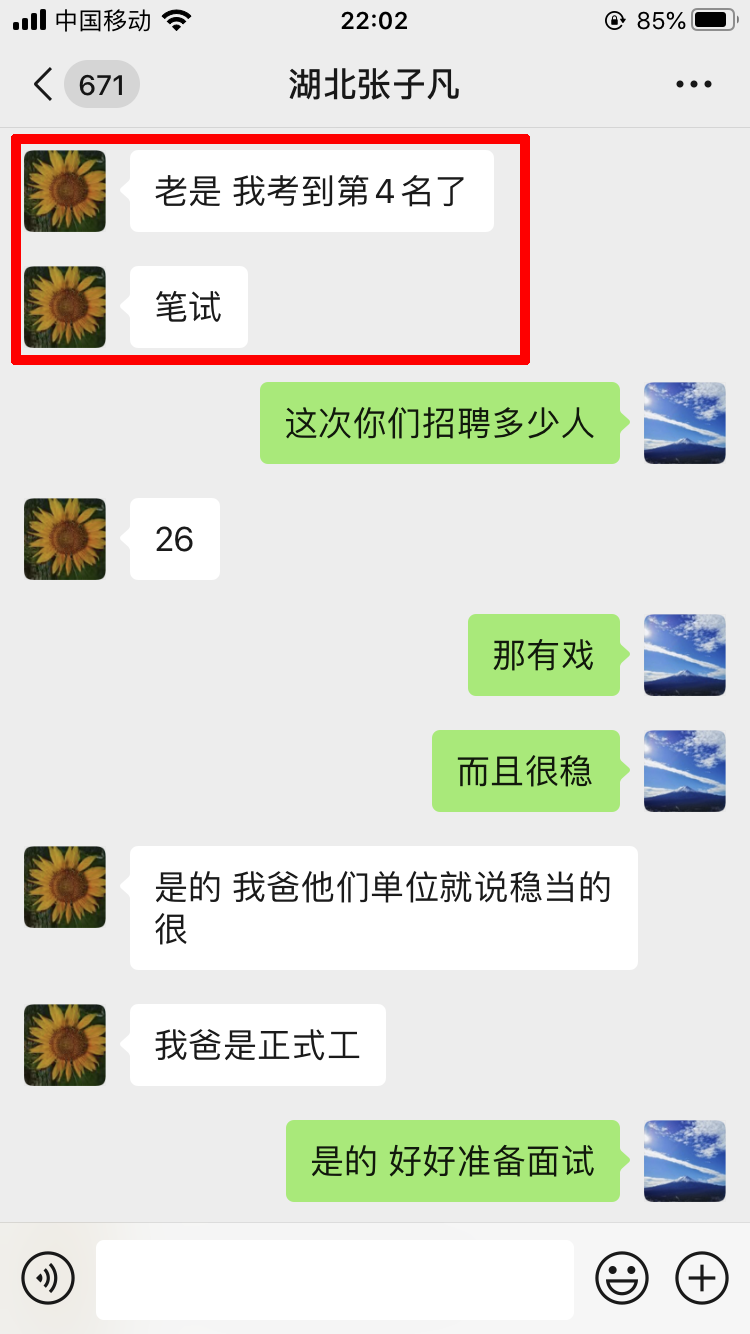
学员评价
推荐阅读:
- 上一篇:2025年百度搜题网页版入口登录(百度搜题网页版入口登录不了)
- 下一篇:没有了