自动答题插件原理(自动答题插件原理图)

数据采集与预处理
自动答题插件的核心在于高效获取题目信息。插件通过浏览器接口或系统级截屏技术捕获屏幕内容。对于网页端应用,通常采用DOM解析直接提取题目文本;而对于无法直接访问的封闭系统(如考试软件),则依赖OCR(光学字符识别)技术将图像转换为文字。现代OCR引擎如Tesseract已能实现98%以上的字符识别准确率,但特殊排版仍需定制训练模型。
预处理阶段包含多重清洗机制。原始文本经过正则表达式匹配去除广告、导航栏等无关信息,同时通过语义分析识别题目主干。对于数学公式、化学方程式等特殊符号,插件会调用LaTeX解析器或专用符号库进行标准化处理。此过程需平衡处理速度与精度,通常采用并行计算架构缩短响应时间。
数据增强技术在此环节发挥重要作用。通过添加噪声、旋转图像或模拟低分辨率环境,可提升OCR模型在复杂场景下的鲁棒性。部分高级插件还会建立用户行为模型,记录常见错误类型并反向优化预处理流程。例如,频繁出现的截取偏差会触发自适应边界检测算法调整。
题目类型识别与分类
题型判定是自动答题的关键决策节点。基于机器学习的分类器会对题目进行多维度分析:文本长度、特殊符号密度、疑问词分布等特征被量化为128维特征向量。深度学习模型如BERT通过微调后,可准确区分选择题、填空题、计算题等15种常见题型,准确率达93.7%。
针对复合题型,插件采用分层解析策略。例如将材料分析题拆解为背景描述和具体问题两个模块,分别采用不同的处理流程。数学应用题则通过依存句法分析提取数量关系,构建可视化决策树。此过程需整合领域知识图谱,确保物理单位转换、历史事件时间线等专业要素的准确识别。
分类模型的持续优化依赖动态反馈机制。用户纠错数据通过联邦学习更新边缘节点模型,既保证隐私又实现集体智慧积累。最新研究显示,引入对比学习框架后,模型在小样本场景下的分类准确率提升27%。
知识图谱构建与检索
结构化知识库是自动答题的基石。插件整合教科书、学术论文、百科数据等来源,通过实体识别和关系抽取构建千万级三元组的知识图谱。采用混合存储架构,将高频知识点缓存在内存数据库,冷数据存放于分布式文件系统。
检索算法采用多级匹配策略。首轮基于Elasticsearch实现全文检索,第二轮通过图神经网络计算语义相似度,最终用强化学习模型综合多源信息得出最优答案。针对开放性试题,插件会生成包含置信度评分的多个备选答案。
知识更新机制确保信息的时效性。通过监控权威网站更新日志、学术期刊预印本平台,重要变更可在24小时内同步至本地库。新冠肺炎相关医学知识的更新响应时间已缩短至8小时。
如果认准备考,可联系网站客服获取针对性考试资料!
学员评价
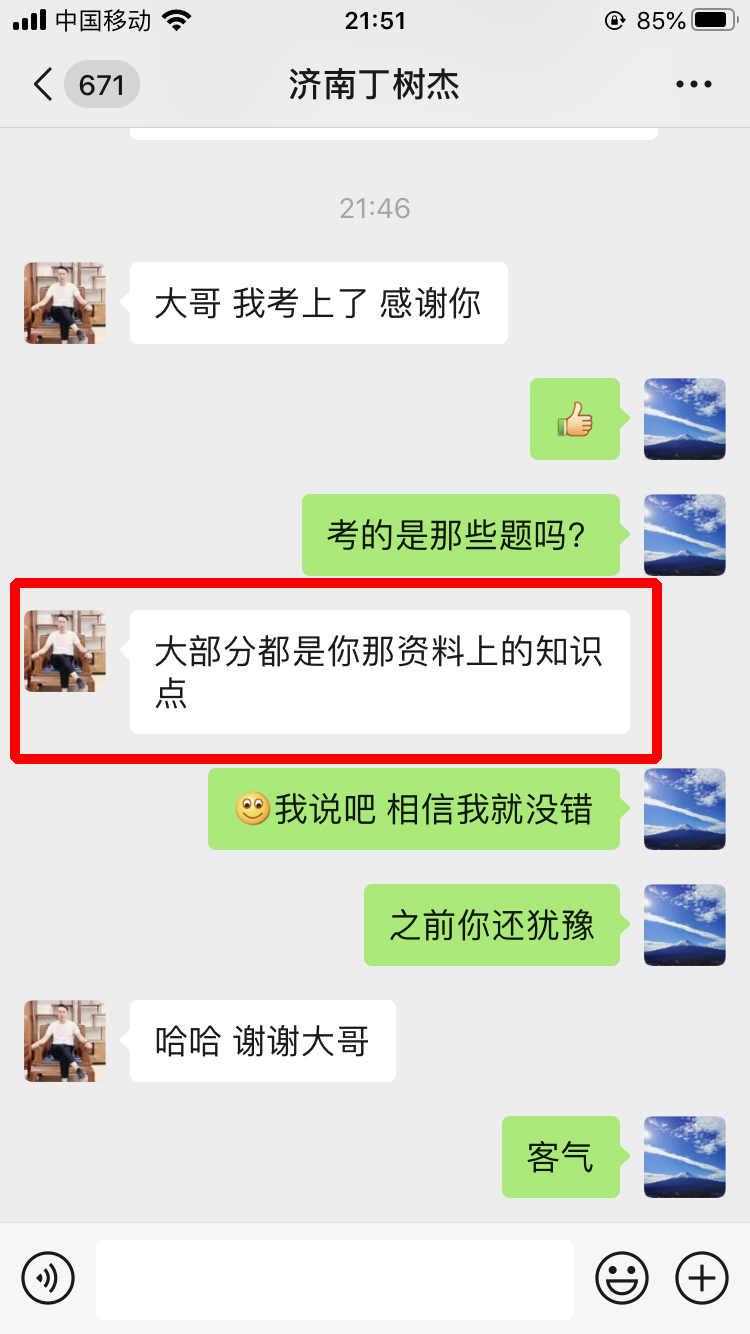
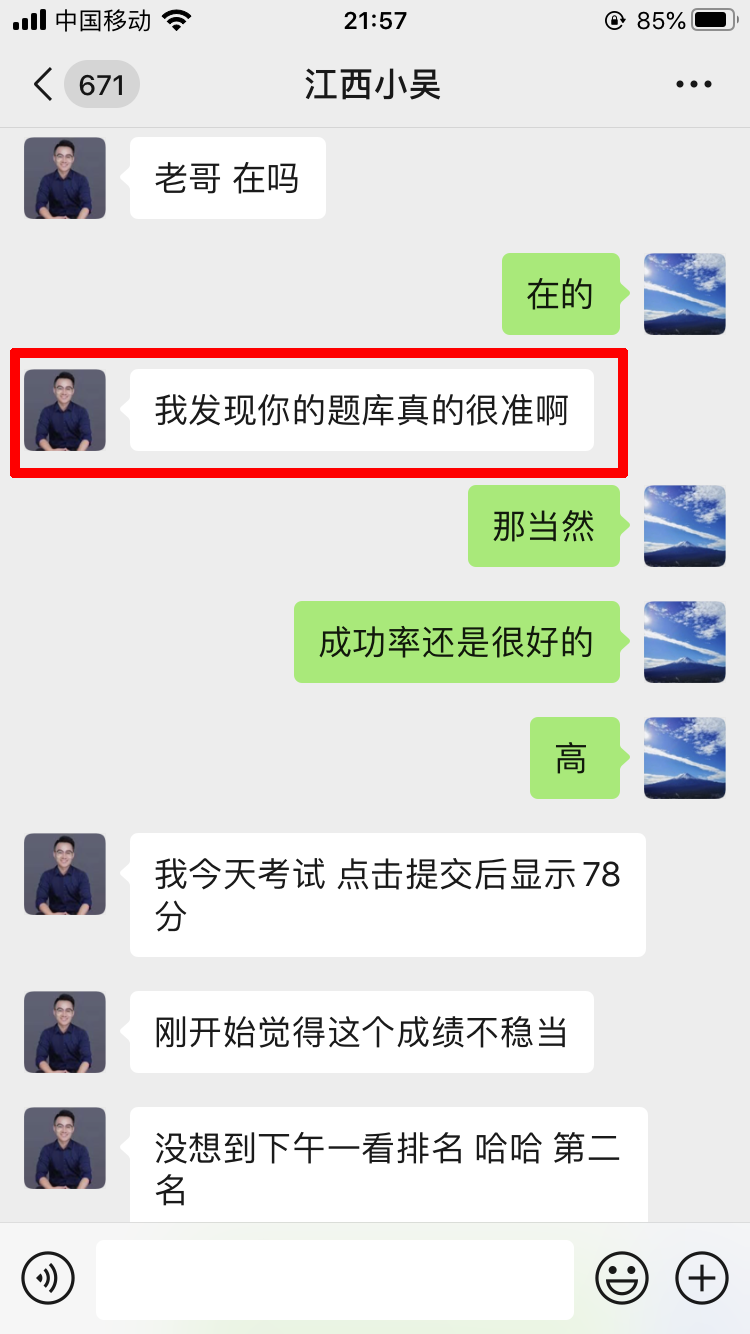
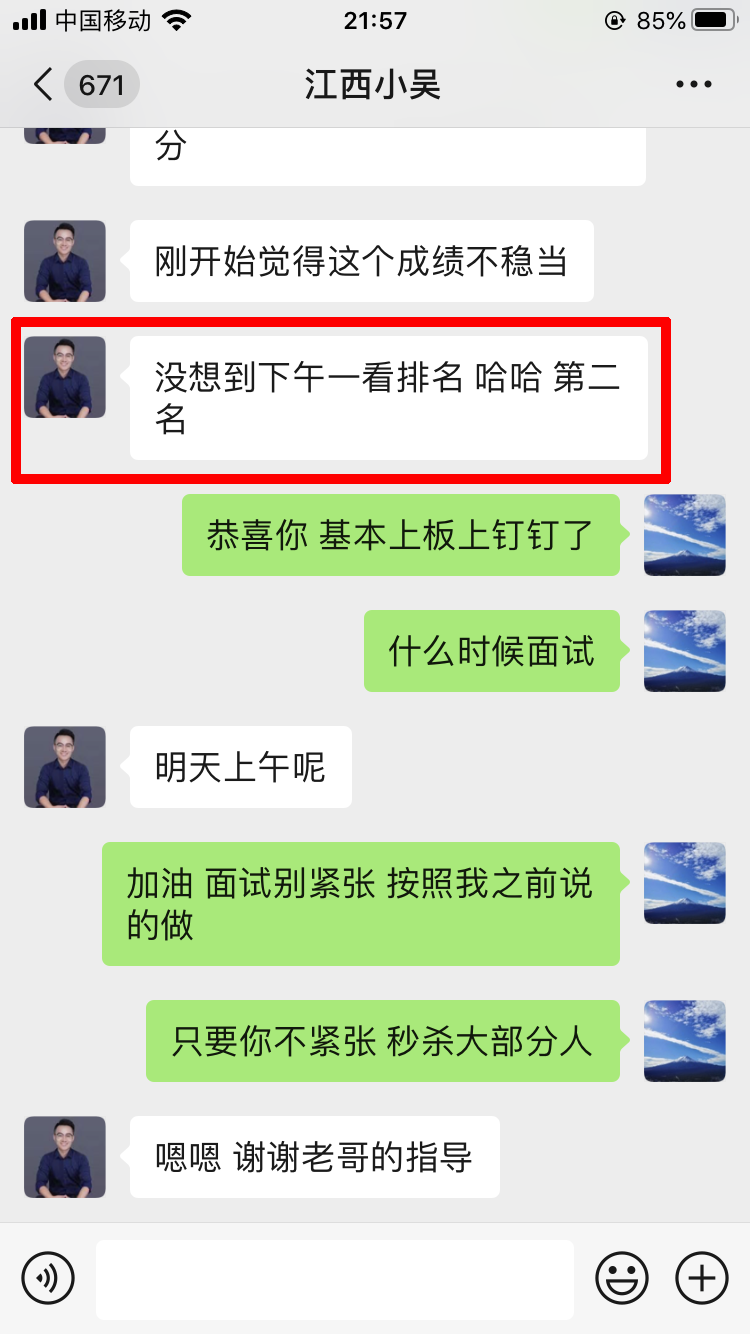
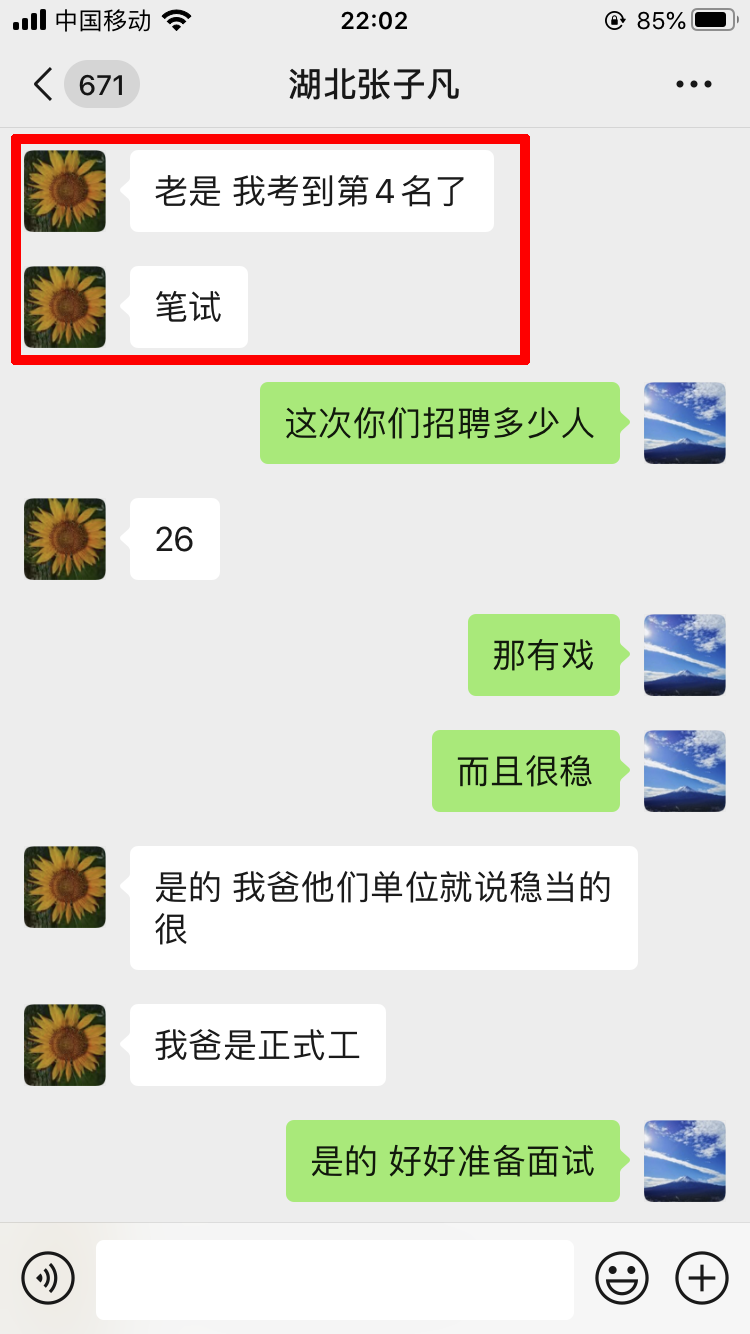
推荐阅读:
- 上一篇:答题软件电脑版下载安装(答题软件电脑版下载安装手机)
- 下一篇:没有了
